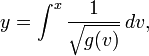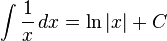$ cat SNP.txt
id Sam_01 Sam_02 Sam_03 Sam_04 Sam_05
Snp_01 2 0 2 0 2
Snp_02 0 1 1 2 2
Snp_03 1 0 1 0 1
Snp_04 0 1 2 2 2
Snp_05 1 1 2 1 1
Snp_06 2 2 2 1 1
Snp_07 1 1 2 2 0
Snp_08 1 0 1 0 1
Snp_09 2 1 2 2 0
I want to convert it to the following format:
id Snp_01 Snp_02 Snp_03 Snp_04 Snp_05 Snp_06 Snp_07 Snp_08 Snp_09
Sam_01 2 0 1 0 1 2 1 1 2
Sam_02 0 1 0 1 1 2 1 0 1
Sam_03 2 1 1 2 2 2 2 1 2
Sam_04 0 2 0 2 1 1 2 0 2
Sam_05 2 2 1 2 1 1 0 1 0
1. rowsToCols from Jim Kent's utility
wget http://hgdownload.soe.ucsc.edu/admin/exe/linux.x86_64/rowsToCols
cat SNP.txt | rowsToCols stdin stdout
2. datamash from GNU
cat SNP.txt | datamash transpose
btw, datamash is really a neat command with many functions, like your swiss-knife for small daily tasks for data scientist. Here is its example page on GNU:
http://www.gnu.org/software/datamash/examples/
We can easily do this in R (e.g.. t(df)), but actually there are also a couple available tools in linux. Here are two I used:1. rowsToCols from Jim Kent's utility
wget http://hgdownload.soe.ucsc.edu/admin/exe/linux.x86_64/rowsToCols
cat SNP.txt | rowsToCols stdin stdout
2. datamash from GNU
cat SNP.txt | datamash transpose
btw, datamash is really a neat command with many functions, like your swiss-knife for small daily tasks for data scientist. Here is its example page on GNU:
http://www.gnu.org/software/datamash/examples/